8. How did the researchers crack the genetic code into amino acid letters for the translation process and mention start and stop codons?
8. How did the researchers crack the genetic code into amino acid letters for the translation process and mention start and stop codons?
answer :
introduction :
Genes that provide instructions for proteins are expressed in a two-step process.
- In transcription, the DNA sequence of a gene is "rewritten" using RNA nucleotides. In eukaryotes, the RNA must go through additional processing steps to become a messenger RNA, or mRNA.
- In translation, the sequence of nucleotides in the mRNA is "translated" into a sequence of amino acids in a polypeptide (protein or protein subunit).
Cells decode mRNAs by reading their nucleotides in groups of three, called codons. Each codon specifies a particular amino acid, or, in some cases, provides a "stop" signal that ends translation. In addition, the codon AUG has a special role, serving as the start codon where translation begins. The complete set of correspondences between codons and amino acids (or stop signals) is known as the genetic code.
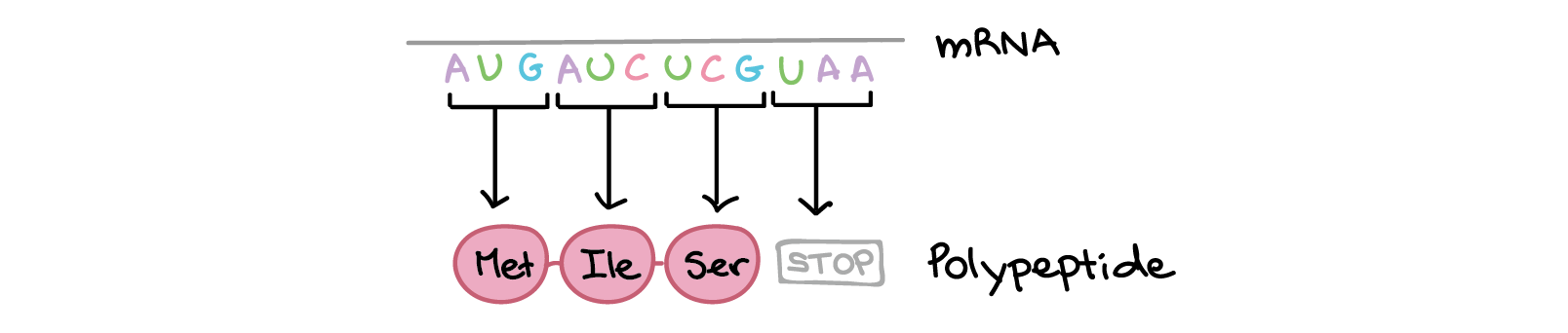
In the rest of this article, we'll more closely at the genetic code. First, we'll see how it was discovered. Then, we'll look more deeply at its properties, seeing how it can be used to predict the polypeptide encoded by an mRNA.
How the genetic code was discovered :
To crack the genetic code, researchers needed to figure out how sequences of nucleotides in a DNA or RNA molecule could encode the sequence of amino acids in a polypeptide.
Why was this a tricky problem? In one of the simplest potential codes, each nucleotide in an DNA or RNA molecule might correspond to one amino acid in a polypeptide. However, this code cannot actually work, because there are 20 amino acids commonly found in proteins and just 4 nucleotide bases in DNA or RNA. Thus, researchers knew that the code must involve something more complex than a one-to-one matching of nucleotides and amino acids.
The triplet hypothesis :
In the mid-1950s, the physicist George Gamow extended this line of thinking to deduce that the genetic code was likely composed of triplets of nucleotides. That is, he proposed that a group of 3 successive nucleotides in a gene might code for one amino acid in a polypeptide.
Gamow's reasoning was that even a doublet code (2 nucleotides per amino acid) would not work, as it would allow for only 16 ordered groups of nucleotides (4, squared), too few to account for the 20 standard amino acids used to build proteins. A code based on nucleotide triplets, however, seemed promising: it would provide 64 unique sequences of nucleotides (4, cubed), more than enough to cover the 20 amino acids.
Properties of the genetic code :
As we saw above, the genetic code is based on triplets of nucleotides called codons, which specify individual amino acids in a polypeptide (or "stop" signals at its end). The codons of an mRNA are “read” one by one inside protein-and-RNA structures called ribosomes, starting at the 5’ end of the gene and moving towards the 3’ end. Let's take a closer look at the genetic code in the context of translation.
Types of codons (start, stop, and "normal") :
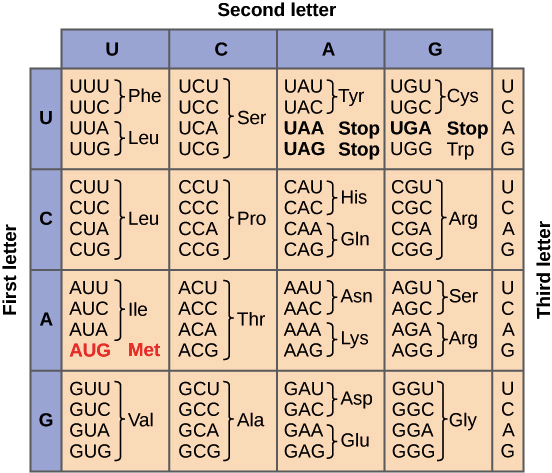
_Image credit: "The genetic code," by OpenStax College, Biology (CC BY 3.0)._
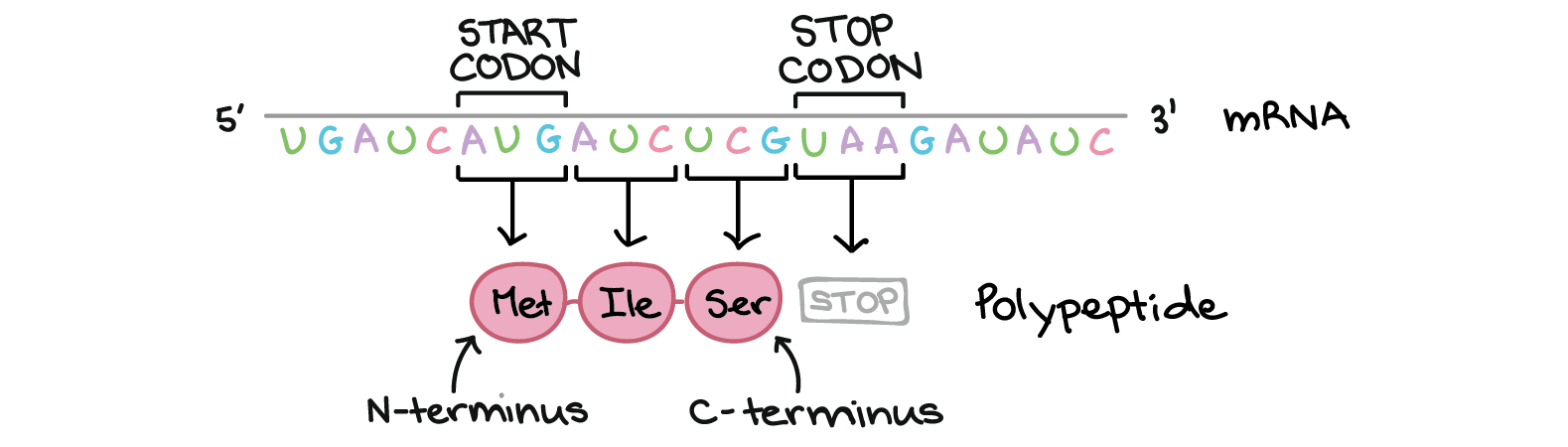
Translation always begins at a start codon, which has the sequence AUG and encodes the amino acid methionine (Met) in most organisms. Thus, every polypeptide typically starts with methionine, although the initial methionine may be snipped off in later processing steps. A start codon is required to begin translation, but the codon AUG can also appear later in the coding sequence of an an mRNA, where it simply specifies the amino acid methionine.
Once translation has begun at the start codon, the following codons of the mRNA will be read one by one, in the 5' to 3' direction. As each codon is read, the matching amino acid is added to the C-terminus of the polypeptide. Most of the codons in the genetic code specify amino acids and are read during this phase of translation.
Translation continues until a stop codon is reached. There are three stop codons in the genetic code, UAA, UAG, and UGA. Unlike start codons, stop codons don't correspond to an amino acid. Instead, they act as "stop" signals, indicating that the polypeptide is complete and causing it to be released from the ribosome. More nucleotides may appear after the stop codon in the mRNA, but will not be translated as part of the polypeptide.
The genetic code is (nearly) universal :
With some minor exceptions, all living organisms on Earth use the same genetic code. This means that the codons specifying the 20 amino acids in your cells are the same as those used by the bacteria inhabiting hydrothermal vents at the bottom of the Pacific Ocean. Even in organisms that don't use the "standard" code, the differences are relatively small, such as a change in the amino acid encoded by a particular codon.
A genetic code shared by diverse organisms provides important evidence for the common origin of life on Earth. That is, the many species on Earth today likely evolved from an ancestral organism in which the genetic code was already present. Because the code is essential to the function of cells, it would tend to remain unchanged in species across generations, as individuals with significant changes might be unable to survive. This type of evolutionary process can explain the remarkable similarity of the genetic code across present-day organisms.
conclusion :



Comments
Post a Comment